The Observability Pipeline
本文的话题是使用 The Observability Pipeline 帮助更好地理解系统。问题产生的背景是现代软件不再局限于裸机+Nagios 这种组合,而是趋向于 cloud-native and container-based systems。可能你 Debug 着,容器就被干没了。所以,要想解决这个问题,就得让应用自己传出结构化的日志记录用于分析 - 这产生了新问题:如何处理这些日志呢?结论是建一条 Observability Pipeline。
监控是关于known-unknowns and actionable alerts, observability 是关于 unknown-unknowns,并帮助开发更容易理解系统行为。以下是开发 The Observability Pipeline 的一些要点:
- 确保日志是 Structured 的。你要写 spec,spec 要能区分 logs, metrics, traces, events 各种数据,spec 要能演化支持版本升级,最好带上 id 帮忙定位,可以带上一些 tag 帮助过滤。
- 需要的话可以在服务里面安装上 Specification Libraries,帮助更好地生成日志,类似 tracing libraries。
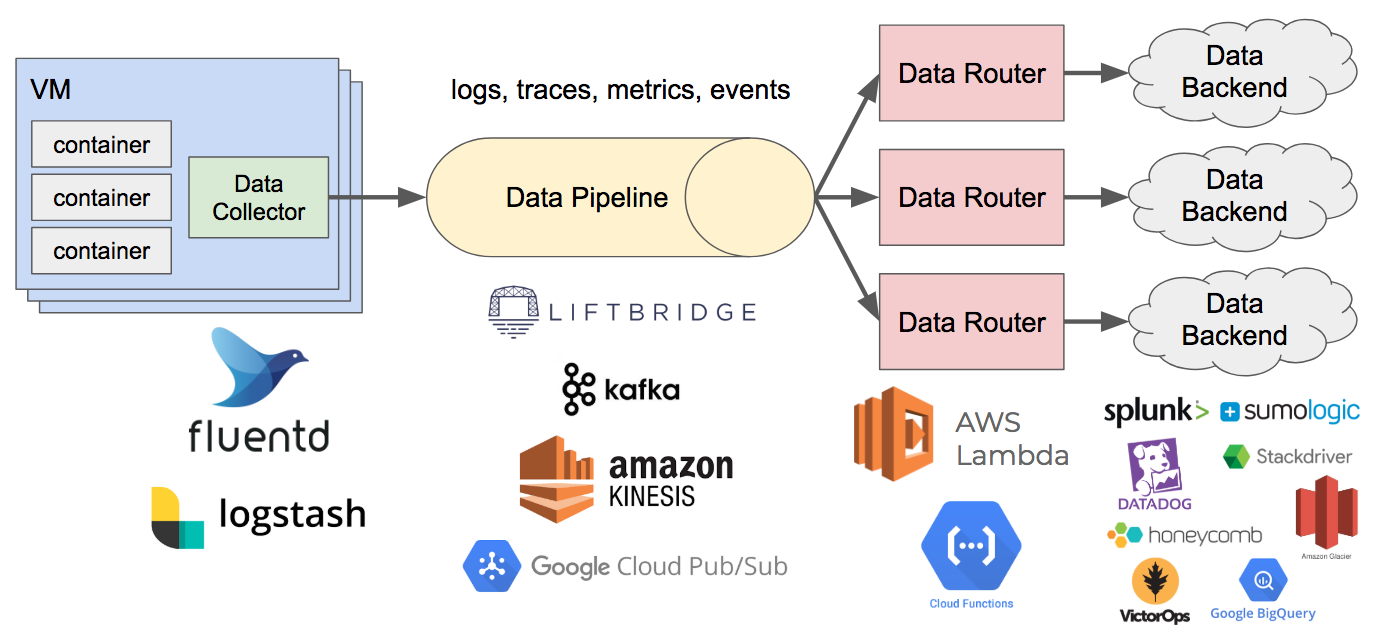
- Data Collector 可以作为 sidecar 安装在容器里或者 host 上,写到 stdout/stderr 或者 Unix domain socket,然后推到 pipeline 里面。很多日志工具都可以用,例如 fluentd。
- Data Pipeline 的核心就是保证高可用,很多工具也可以用,例如:kafka, kinesis, 等等
- Data Router 用于过滤数据,接在 Pipeline 后面,把数据发送到合适的后端去,这种地方用 serverless 什么的就很方便。
整个架构大概长这样:
当然,这个架构不是一天造出来的,你可以当作 CI/CD 流水线一样一直去打磨它。